




Table of Contents
- Introduction to DataOps
- Key Principles of DataOps
- Differentiation between DataOps vs DevOps
- DataOps Workflow
- Tools and Technologies in DataOps
- Data Quality and Governance in DataOps
- Future Trends in DataOps
- Conclusion
Introduction to DataOps:
DataOps can be defined as a set of practices and principles aimed at improving the speed, quality, and reliability of data analytics and operations. Unlike traditional data management approaches, which often involve siloed teams and manual processes, it promotes collaboration, automation, and continuous integration/continuous delivery (CI/CD) throughout the data lifecycle.
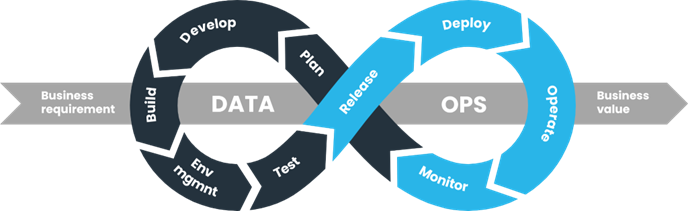
Key Principles of DataOps:
It is built on several key principles:
- Automation: Automating repetitive tasks such as data ingestion, transformation, and deployment reduces manual effort and ensures consistency.
- Collaboration: Encouraging cross-functional collaboration between data engineers, data scientists, and other stakeholders promotes shared ownership and faster decision-making.
- Continuous Integration/Continuous Delivery (CI/CD): Adopting CI/CD practices enables rapid and reliable delivery of data pipelines and analytical insights, reducing time-to-value.
- Monitoring and Feedback: Implementing robust monitoring and feedback loops allows teams to identify issues early and iterate quickly, improving overall data quality and reliability.
Differentiation between DataOps vs DevOps -
Aspect | DevOps | DataOps |
Focus | Software development and deployment lifecycle | Data operations throughout the data lifecycle |
Domain | Software development, deployment, and operations | Data-related processes, including ingestion, processing, and analysis |
Processes & Tools | Version control systems, CI/CD servers, configuration management tools, containerization platforms | Data integration platforms, data warehouse solutions, data quality tools, monitoring and logging tools |
Objectives | Accelerate software delivery, increase deployment frequency, reduce lead time for changes, improve collaboration | Improve speed, quality, and reliability of data analytics processes, enable rapid insights and data-driven decision-making |
Culture & Collaboration | Promote collaboration, shared responsibility, and continuous improvement across development and operations teams | Foster collaboration and shared ownership among data engineers, data scientists, and other stakeholders involved in data operations |
Metrics & Outcomes | Deployment frequency, lead time for changes, MTTR, deployment success rate | Data quality, pipeline throughput, time to insights, data availability, data-related errors or anomalies |
DataOps Workflow:
The workflow typically involves the following stages:
- Data Ingestion: Collecting data from various sources, such as databases, files, APIs, and streaming platforms.
- Data Processing: Transforming raw data into a usable format through cleansing, enrichment, and normalization.
- Data Analysis: Performing exploratory data analysis, modeling, and visualization to extract insights and derive value.
- Deployment: Deploying data pipelines, models, and analytical solutions into production environments for ongoing use.
Tools and Technologies in DataOps:
- Apache Airflow: Airflow is an open-source workflow orchestration platform that allows users to programmatically author, schedule, and monitor data pipelines. It supports tasks such as data ingestion, transformation, and workflow automation.
- Apache NiFi: NiFi is an open-source data integration and routing tool that enables the automation of data flows across distributed systems. It provides a visual interface for designing, monitoring, and managing data pipelines in real-time.
- Snowflake: Snowflake is a cloud-based data warehouse platform that allows users to store, query, and analyze large volumes of structured and semi-structured data. It offers scalability, performance, and concurrency features for data analytics workloads.
- Amazon Redshift: Redshift is a fully managed data warehouse service provided by Amazon Web Services (AWS). It enables users to analyze petabytes of data with high performance and cost-effectiveness, leveraging SQL-based querying and data integration capabilities.
- Trifacta: Trifacta is a data preparation platform that empowers users to clean, transform, and enrich raw data for analysis. It provides intuitive data wrangling features and machine learning-based suggestions for improving data quality and usability.
- Informatica Data Quality: Informatica offers a suite of data quality tools that enable users to profile, cleanse, standardize, and monitor data across heterogeneous sources. It includes capabilities for data validation, deduplication, and enrichment.
- Prometheus: Prometheus is an open-source monitoring and alerting toolkit designed for monitoring the performance and health of cloud-native applications and infrastructure. It collects time-series data and triggers alerts based on predefined thresholds and rules.
- Grafana: Grafana is an open-source visualization platform that allows users to create, explore, and share dashboards and graphs based on data from various sources. It integrates with Prometheus and other monitoring systems for visualizing metrics and logs.
Data Quality and Governance in DataOps:
- Data Profiling: DataOps teams perform data profiling to understand the structure, content, and quality of datasets. This involves analyzing metadata, identifying patterns, and detecting anomalies to assess data quality.
- Data Cleansing: DataOps automates data cleansing processes to address issues such as missing values, duplicates, inconsistencies, and outliers. This ensures that data is standardized, normalized, and ready for analysis.
- Data Validation: DataOps implements automated data validation checks to verify the accuracy, completeness, and consistency of data against predefined rules and constraints. This helps identify errors and discrepancies early in the data pipeline.
- Data Policies and Standards: DataOps establishes data governance policies and standards to define how data should be managed, accessed, and used across the organization. This includes data classification, access controls, retention policies, and privacy regulations compliance.
- Data Lineage: DataOps tracks data lineage to provide visibility into the origins, transformations, and dependencies of data as it moves through the pipeline. This helps ensure data traceability, auditability, and regulatory compliance.
- Data Security: DataOps implements security measures to protect sensitive data from unauthorized access, disclosure, and misuse. This includes encryption, access controls, authentication, and monitoring to safeguard data privacy and confidentiality.
- Data Catalog: DataOps maintains a centralized data catalog or metadata repository to catalog and document data assets, including their attributes, definitions, ownership, and usage. This promotes data discoverability, reuse, and collaboration across teams.
- Data Stewardship: DataOps assigns data stewards responsible for overseeing data governance practices, resolving data quality issues, and enforcing data policies within their respective domains. This ensures accountability and ownership of data assets.
- Data Quality Monitoring: DataOps continuously monitors data quality metrics and KPIs to detect deviations, anomalies, and trends that may indicate data quality issues. Automated alerts and notifications trigger proactive interventions to address issues promptly.
- Feedback Loops: DataOps establishes feedback loops to capture user feedback, data quality issues, and performance metrics, enabling continuous improvement of data pipelines and governance processes. This fosters a culture of learning and adaptation.
- Root Cause Analysis: When data quality issues occur, DataOps conducts root cause analysis to identify the underlying causes, such as system failures, process inefficiencies, or human errors. This informs corrective actions and preventive measures to mitigate future incidents.
By integrating data quality and governance practices into the workflow, organizations can ensure that their data assets are trustworthy, compliant, and fit for purpose. This enables data-driven decision-making, fosters innovation, and enhances organizational agility and competitiveness in today’s data-driven landscape.
Future Trends in DataOps:
The future holds several exciting trends and advancements that are poised to further enhance data operations and analytics capabilities. Here are some of the key future trends in DataOps:
- AI and Machine Learning Integration: As AI and machine learning technologies continue to advance, they will play a significant role in automating and optimizing various aspects of DataOps. AI-driven automation can streamline tasks such as data cleansing, anomaly detection, predictive modeling, and even decision-making within data pipelines.
- Serverless Architectures: Serverless computing offers scalability and cost-efficiency benefits by abstracting infrastructure management from application development. In the context of DataOps, serverless architectures enable more dynamic and resource-efficient execution of data workflows, reducing operational overhead and enabling faster time-to-insights.
- DataOps-as-a-Service (DaaS): Similar to the rise of DevOps-as-a-Service (DaaS) offerings, we can expect to see the emergence of DataOps-as-a-Service platforms that provide managed solutions for data pipeline orchestration, data integration, data quality management, and analytics. These platforms will democratize DataOps capabilities, particularly for smaller organizations with limited resources.
- Real-time Data Processing: With the increasing demand for real-time insights and decision-making, DataOps will evolve to support real-time data processing and analytics. Technologies such as stream processing frameworks (e.g., Apache Kafka, Apache Flink) and in-memory databases will enable organizations to ingest, process, and analyze streaming data at scale with low latency.
- Data Mesh Architecture: Data mesh is an architectural paradigm that advocates for decentralizing data ownership and governance by treating data as a product. In a data mesh architecture, data is managed and curated by decentralized, cross-functional teams, which aligns well with the principles of DataOps. This approach promotes agility, scalability, and autonomy in data operations.
- Ethical DataOps: As concerns around data privacy, security, and ethical use of data continue to grow, DataOps practices will need to incorporate principles of ethical data governance and responsible AI. Organizations will need to implement safeguards to ensure that data operations comply with regulations and ethical standards, while also promoting transparency and accountability.
- Hybrid and Multi-cloud DataOps: With the increasing adoption of hybrid and multi-cloud environments, DataOps will need to adapt to manage data across disparate cloud platforms and on-premises infrastructure. Hybrid DataOps solutions will enable seamless integration, orchestration, and management of data pipelines and analytics workloads across hybrid and multi-cloud environments.
- Self-service DataOps: Empowering business users and domain experts to participate in data operations through self-service tools and platforms will become increasingly important. Self-service DataOps solutions will enable non-technical users to access, analyze, and derive insights from data independently, reducing reliance on specialized data engineering and IT teams.
- DataOps for IoT and Edge Computing: The proliferation of Internet of Things (IoT) devices and edge computing infrastructure generates vast amounts of data at the edge of networks. DataOps practices will evolve to support edge data processing, analytics, and decision-making, enabling organizations to extract value from IoT-generated data in real-time.
- Quantum DataOps: While still in its nascent stages, quantum computing holds the potential to revolutionize data processing and analytics by performing complex computations at unprecedented speeds. In the future, DataOps will need to adapt to leverage quantum computing capabilities for tasks such as optimization, simulation, and pattern recognition, opening up new frontiers in data-driven innovation.
Conclusion:
Frequently Asked Questions About DataOps
Marlabs designs and develops digital solutions that help our clients improve their digital outcomes. We deliver new business value through custom application development, advanced software engineering, digital-first strategy & advisory services, digital labs for rapid solution incubation and prototyping, and agile engineering to build and scale digital solutions. Our offerings help leading companies around the world make operations sleeker, keep customers closer, transform data into decisions, de-risk cyberspace, boost legacy system performance, and seize novel opportunities and new digital revenue streams.
Marlabs is headquartered in New Jersey, with offices in the US, Germany, Canada, Brazil and India. Its 2500+ global workforce includes highly experienced technology, platform, and industry specialists from the world’s leading technical universities.
Marlabs Inc.(Global Headquarters) One Corporate Place South, 3rd Floor, Piscataway NJ – 08854-6116, Tel: +1 (732) 694 1000 Fax: +1 (732) 465 0100, Email: contact@marlabs.com.