



To achieve a successful and efficient data ingestion process, it is imperative to have a robust and scalable data ingestion pipeline. The pipeline must include features such as checkpointing, logging, and error handling to ensure the reliability and consistency of the data ingestion process. Additionally, it should be able to handle various data formats, ingestion velocities, and sources while supporting parallel processing and scaling with increasing data volumes.
In today’s fast-paced business world, having a sustainable data ingestion pipeline is no longer an option, it’s a must-have. By investing in a dependable data ingestion pipeline, organizations can significantly enhance their data analysis capabilities, make informed decisions, and gain a decisive edge in the market. With deeper insights into their operations, businesses can unlock untapped opportunities, improve operational efficiency, and drive growth. Therefore, building a sustainable data ingestion pipeline should be a top priority for all businesses that want to thrive in today’s data-driven landscape.
To fully capitalize on the value of data, enterprises must prioritize implementing the following measures for enhanced data reliability:
Checkpointing is a vital technique used in data ingestion pipelines to keep track of data transfer progress. It ensures that any failures can be recovered without losing any data. By setting checkpoints at different pipeline stages, such as before and after each data transfer, the pipeline can resume from the last successful checkpoint in case of any failure. This helps minimize data loss and ensures data consistency throughout the ingestion process.
Tracking and Logging is another essential technique used in data ingestion pipelines. It allows for the entire data ingestion process to be tracked and helps in identifying and diagnosing any issues that may arise. Logging provides an audit trail of the ingestion, which may be essential for compliance and regulatory purposes.
Auditing is key during the data ingestion process. While checkpointing and logging are crucial techniques for ensuring data integrity, maintaining audit logs and ingestion status can impact pipeline performance. Therefore, it is important to optimize the pipeline for speed and resource usage to ensure efficient data transfer while incorporating auditing and checkpointing techniques.
Parallel Processing is a technique used to distribute the workload across multiple processors to enhance the efficiency of data transfer. It is an effective way to achieve a performance-based pipeline. By dividing the workload across multiple processors, data transfer can be speeded up considerably. This technique is especially useful when working with large datasets that require significant processing power. Parallel processing can be used in conjunction with other techniques such as caching and compression to optimize the pipeline for performance. By utilizing these techniques, the pipeline can handle larger volumes of data, process it faster, and reduce the time taken to complete tasks.
Marlabs has revolutionized the process of Application Programming Interface (API) ingestion with an innovative framework that is designed to optimize performance and prevent data loss. With this framework, you can rest assured that your data is in safe hands. The framework seamlessly and efficiently integrates with AWS services to extract data from an API and store it incrementally in Amazon S3 storage. What’s more, the framework employs advanced checkpointing and logging techniques that identify the causes of any failures that may occur, ensuring data integrity. With Marlabs’ automated API ingestion framework, you can streamline your data acquisition process and focus on what really matters – growing your business.
Data Flow
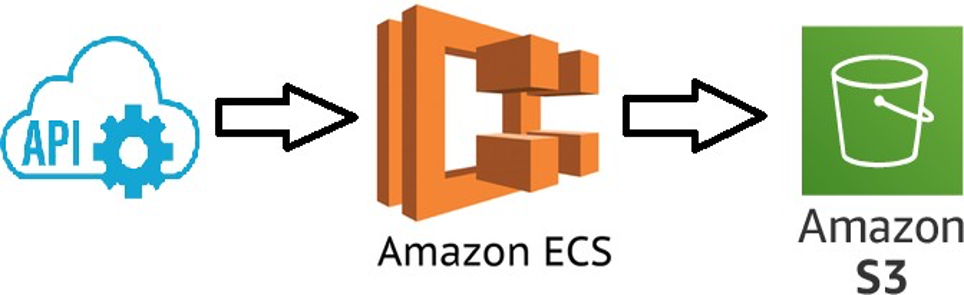
Revolutionize Your AWS Environment with High-Level API Ingestion
The ingestion framework is launched using an Amazon ECS container and follows a well-designed high-level approach to ensure efficient data transfer while minimizing data loss. The framework leverages the following steps to achieve its objectives:
- The framework utilizes DynamoDB to keep track of previous runs and determine the current checkpoint from which to pull the data. This guarantees that data is properly checked and that there is no loss of data during the ingestion process.
- To efficiently handle large amounts of data, the framework leverages parallelism to extract data from the source API.
- The framework has a dedicated queue for failed chunks of data, which demonstrates a strong fault-tolerant design. This queue allows for automatic retries of unsuccessful data chunks at the end of the current pull, reducing the risk of data loss and promoting data consistency during the ingestion process.
- CloudWatch logs are used to print the status of the run on the console, providing real-time visibility into the ingestion process.
- The framework maintains a log file of the run in separate storage, enabling debugging of historical runs.
- The framework stores the extracted data in S3, leveraging parallelism for further analysis. This helps to optimize performance and ensure that the data is available for analysis.
- Once the entire process is complete, the framework updates the current run status in DynamoDB, ensuring that the ingestion process is complete, and the data is consistent.
- The framework also has an automated fail-over mechanism that triggers in case there are many failed API hits in the current run. This ensures that the ingestion process continues seamlessly, minimizing the impact of any failures on the ingestion process.
Discover the Advantages of Marlabs’ API Ingestion Framework
The ingestion framework leverages several components of the AWS ecosystem that offer several benefits, as outlined below:
- AWS Fargate integrated with Amazon ECS: This component relieves the burden of host management, planning, and container task segregation safety. With Docker technology, applications can be deployed automatically as portable containers that can be used in various settings. This helps to reduce operational overhead, increase scalability, and enable faster deployment times.
- DynamoDB: This fully managed database offering provides a serverless, scalable, and highly available database solution that does not require any infrastructure management. DynamoDB offers single-digit response times, and globally accessible tables, and improves the overall user experience by providing seamless and consistent access to data. By using DynamoDB to maintain the state of the ingestion process, the framework ensures that data is checked and that there is minimal data loss.
- CloudWatch: This service enables real-time monitoring of AWS resources, providing essential metrics such as CPU utilization, latency, and request counts, which can be used to optimize performance and troubleshoot issues. CloudWatch also enables users to specify additional metrics to be monitored, such as memory usage, transaction volumes, or error rates, ensuring comprehensive visibility into the ingestion process.
Adding value to your Data
The impact of the ingestion framework implemented by Marlabs is significant for the business. By ensuring the timely delivery of data without any loss, the framework accelerates the analytics requirements and generates insights much more quickly. This data is particularly important as it tracks Mobile/Chatbot Interactions with customers, which can provide valuable insights into customer satisfaction and retention.
The ability to analyze customer queries, call forwarding patterns, agent performance, and sales data can help businesses improve their customer service and sales strategies. By analyzing this data, companies can gain insights into the customer experience and identify areas for improvement. This can ultimately lead to increased customer satisfaction and retention, which is critical for business growth.
Additionally, by automating the ingestion process and leveraging AWS services, the framework helps to reduce operational overhead and increase scalability, which can save businesses time and resources. Overall, the framework has a significant impact on business operations and can drive improvements in customer satisfaction, retention, and overall performance.

The ingestion framework developed by Marlabs offers substantial benefits in terms of reducing development work effort. It allows for the reuse of the framework to extract data from any API system and ingest it into near real-time AWS Cloud, reducing development time and effort by 60%. This is especially useful for businesses that require different data pipelines to manage important business data.
By using this framework, businesses can quickly and easily set up data pipelines for various systems and guarantee the timely and accurate ingestion of data. This not only reduces development costs but also helps businesses make faster decisions based on the information they collect.
Moreover, businesses can stay ahead of their competition by making more informed decisions based on real-time data. By reducing the time it takes to develop and implement new data pipelines, businesses can be more agile and respond more quickly to changing market conditions.